●《张謇研究(2024)· 成果精选》 ●
张謇研究数据库建设与应用研究
李 强 钱智勇
(南通大学图书馆,江苏 南通 226019)
摘 要:该文概述了南通大学张謇研究文献数据库的建设背景、收录范围、数据库的平台架构,功能结构,张謇研究文献数字化过程中的电子书加工、元数据编目操作流程,以及检索功能的实现。在此基础上提出了利用张謇研究数据库进行张謇研究社会网络分析和基于本体的张謇研究与江海文化深度开发的构思与应用。以大数据、人工智能技术为依托,整理分析文献与文献、文献与人物、人物与人物之间关联关系,为“讲好张謇故事、传承张謇精神”提供一套完整的知识管理平台。在此基础上实现“江海文化”文献实例知识的关联分析与推理查询,有益于推动知识组织方法在地方文化领域的数字化实践,推动地方传统文化的传承与发展。
关键词:张謇;数据库;TPI;知识管理;数字化;应用
张謇为清末状元,是“中国近代第一城”(工程院院士吴良镛语)——南通的缔造者。早在1956年2月毛泽东主席在接见黄炎培时,曾表示,提起民族工业,在中国近代史上有4个人不能忘记,其中“轻工业不能忘记海门的张謇”。2020年习近平总书记在南通考察时指出:“张謇是中国民营企业家的先贤和楷模”,2020年习近平总书记在企业家座谈会上称张謇是“爱国企业家的典范”[1]。张謇也是南通大学创始人。本文通过南通大学张謇研究文献数据库的建设和应用研究,实现“江海文化”文献实例知识的关联分析与推理查询,有益于推动知识组织方法在地方文化领域的数字化研究,推动地域传统文化的传承与发展[2]。
1.张謇研究数据库的建设基础
张謇高举“实业救国”“教育兴国”的大旗,立足南通,惠及全国。一个多世纪以来,南通大学秉持张謇精神,坚守“道德优美、学术纯粹”的教育初心,培养时代新人;坚持“祈通中西、力求精进”的教育原则,赋予新的时代内涵;坚定“学必期于用、用必适于地”的教育理念,扎根中国大地办教育。近年来,南通大学坚决贯彻执行习近平总书记关于哲学社会科学工作的重要论述,坚持把党的领导贯穿到哲学社会科学工作的全领域、全过程。
20世纪30年代以来,国内外近代史学者持续不断开展张謇及其相关文献研究,成立了多个张謇研究机构,如江苏省张謇研究会、南通市张謇研究中心、南通大学张謇研究所、海门张謇研究会等。自1987年举办了首届张謇国际学术研讨会以来,至2015年已在南京、北京、南通、上海等地举办了六届会议,影响深远。第七届研讨会将在2023年张謇诞辰170周年之际在南通市举办[3]。有关张謇先生研究的专著、论文和网络上的文章数以万计。对中国知网(CNKI)以主题词“张謇”进行“篇关摘”检索结果显示,期刊研究论文2386篇,博硕士学位论文176篇,还有数百篇会议报纸及其他文献等,网上OPAC书目查询结果显示:国家图书馆约有368种张謇研究相关论著,上海图书馆、南京图书馆、北京大学图书馆、复旦大学图书馆、南京大学图书馆等国内知名图书馆也有不同程度的收藏,其中当以南通市图书馆、南通大学图书馆收藏为最多。南通是张謇先生的故乡和创办实业的主要地区,南通市图书馆、档案馆以及南通大学图书馆收藏有大量张謇先生的著作、文章、档案、图片、音视频等珍贵历史资料。过去,由于技术、人力、研究方式、政策指引等因素,使得研究工作在一定程度上遇到了很多困难,早期的数字化工作甚至还需要大量的人工参与,海量的张謇研究资料分散于各研究场所,且网络上的张謇研究资源较为分散且质量不一;因此需要收集与张謇有关的名录、论文、原著、照片、图像、音视屏等各种知识信息,然后利用数字化技术和文献知识组织理论、技术、工具对其进行加工、整理,使之合理呈现,最终形成张謇研究文献特色数据库,以帮助研究张謇的学者研究,为网络用户提供相关文献资源。
南通大学图书馆长期致力于张謇学文献的收集、整理与保护,构建张謇特色数据库,利用数字化技术、语义知识组织工具和人工智能新方法对张謇文献进行数字化保护和利用。综合利用国内外领先的古籍数字人文平台和古籍资源库收集张謇手稿、档案、信札、诗文等原始文献。采用机器OCR识别辅助人工校对濒危文献,将图像文件转为可编辑的文档,再利用关键词精准定位整理古籍文献。通过关系图谱链接人物、地域以及时间,关联多种资源类型数据进行展示,把文化背后的关系找出来并以图片的方式显示。早在2003年起南通大学图书馆规划建设张謇研究特色数据库,2005年该数据可被列入江苏省高校文献信息保障系统(Jalis)二期特色数据库建设子项目[4]。2011年该数据库被教育部“211工程”高等教育文献保障系统三期“专题特色数据库”子项目立项。2012年在Calis三期全国高校专题特色库子项目验收评比中被评为二等奖。2013年签订Jalis特色资源整合平台项目参建协议,张謇研究特色数据库对全省高校提供开放服务,成为南通地区江海文化研究和南通大学国家级精品课程《中国古代文学》的重要线上资源。经过20余年的资源收集、整理和研究,2021年,张謇研究数据库建设正式成为南通大学图书馆“十四五”重点建设项目。目前,南通大学图书馆在此基础上正在以大数据、人工智能技术为依托,整理分析文献与文献、文献与人物、人物与人物之间关联关系,按需呈现知识图谱,为“讲好张謇故事、传承张謇精神”提供一套完整的知识管理平台。下文结合实践论述张謇知识库建设的架构、子系统功能及其实现。
2.基于TPI平台构建张謇研究数据库
张謇研究文献数据库建设是基于清华同方TPI6.0平台,张謇研究文献数字化的含义包括两层含义:一是对原有已收集到的文献进行数字化加工转化,即把以纸张为载体的印刷版文献信息利用光学字符识别转化为用计算机存储设备存储的电子版信息,并实现形式转换后的计算机管理,网络传输和数字化存取。二是对转化后的电子版信息进行采集加工,建设新的数字化文献资源,进行整合、组织、分类形成东亚文献的数字化资源体系,通过网络供远程用户检索、查询和利用[5]。清华同方TPI专业数据库制作管理系统是同方知网(北京)技术有限公司自主研制的数字化图书馆资源加工与发布平台,它是一套基于网络平台上用于知识仓库创建、生产、管理、维护和发布的工具软件系统。TPI的加工系统包括内容管理平台、电子书制作工具(Bookshop)、元数据编目系统。实现原始文献资料的数字化和组织;内容发布(CPS)、检索网关与TPI检索服务器一起实现了资源发布[6]。
2.1 平台总体架构
张謇研究数据库建设平台使用的检索系统是基于清华同方自主开发的KBASE数据库管理系统,能够实现信息的组织、存储与检索。它是以管理文本、网页、档案、文献等非结构化数据为主的数据库管理系统,拥有高效、准确的全文检索特点,全文检索速度快,能够做到实用化的数据库管理系统;同时支持服务器群集,可以将多个独立的服务器整合,从而使得非结构化数据存储管理能力强大,能够为千万用户提供稳定的信息检索服务;基于关系数据库全文检索网关可以整合多种异构数据源,为用户提供信息资源的统一搜索;还有先进的中文智能信息处理能力、易用的检索语言、支持多种编码等多个特点。
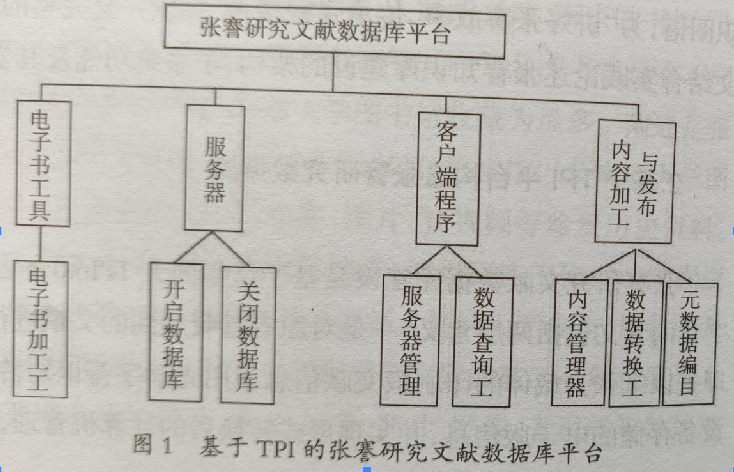
张謇研究文献资源数字化建设的加工系统基于清华同方TPIVer6.0信息资源建设与管理平台,其主要功能包括内容管理平台、电子书制作工具、数据库制作工具(见图1)。支持的元数据标准格式为DC、MARC,同时也支持与其他元数据之间的映射与转换。针对都柏林核心元数据集DC简练、易于理解、可扩展并且能够和其他元数据形式进行桥接的特性[7],能够使图书馆的数字资源很轻松地实现共建共享。此外该平台的黑白二值图像压缩技术使得数据占用的存储空间较少,能够提高信息传播速度。
2.2 Bookshop电子书加工系统
Bookshop是清华同方光盘股份有限公司自主研发的电子书加工工具。通过该工具可以把书籍、报刊、公文等各类纸张文档,通过书页扫描、书页图像处理、目录树编改、书页压缩等过程简单快速地形成电子书籍。也可以把已有各种电子文件,如WORD、PDF、HTML、PS、S2、S72、PS2、PSD、TXT等格式文件,通过本公司自主研发的打印驱动转化为电子书籍。
Bookshop支持各类纸张文档加工成电子书的全过程。其中包括书页图像扫描及管理、书页图像处理、书页图像识别导入及编改、目录加工处理、书页图像及目录合并形成电子书。为适应大规模图书加工业务,该工具对部分工艺还设计了批处理工作方式,用于电子书流水线加工[8]。BookShop包含书页加工过程中所必需的图像处理功能,包括书页高速成批扫描、自动倾斜校正、去噪、剪裁、翻转、灰度图像页自动搜索、灰度区自动标记、灰度图像页亮度及对比度的调整。Bookshop还具有为图书加工所设计的特殊图像处理功能,如整书去除装订孔、整书裁边、内容居中等。Bookshop对上述大部分工艺设计了批处理工作方式,以适应流水线加工。Bookshop支持批图像处理,包括批图像反相、批图像翻转180、批图像右转90、批图像左转90、批图像倾斜校正、批图像去躁、批图像版心校正、本书图像边缘抹白、本书剪裁装订孔、本书裁边、本书增加图章、智能二值化及处理。在书页列表区(书页树)中选择要识别的图像页,选择“文档处理/图像识别”菜单项,或在文档处理栏上点击“图像识别”按钮,Bookshop将选择的图像页进行识别。可以在“识别结果区”参照“图像显示区”修改识别不正确的文字。Bookshop支持全部图像识别功能。
Bookshop目录识别利用目录块文字信息,对全文进行搜索、识别,从而自动生成目录树。Bookshop提供方便的、可视化的目录树编改环境。可修改目录项对应的物理页码、增加目录项、删除目录项和移动目录项等。对于无目录的文档,利用该工具还可以手工建立目录树,以利于导航浏览。Bookshop生成电子书模块对书页扫描图像进行压缩、打包处理,形成电子书。Bookshop还能利用打印驱动把WORD、PDF、HTML、PS、S2、S72、PS2、PSD、TXT等已有的各种电子文件格式转换为浏览器可识别的NH文件格式。该模块也具备批处理能力。如果有目录树,Bookshop在生成电子书的过程中,自动把目录树并入打包文件中,形成带目录树的电子书。
2.3 元数据编目系统。
TPI6.0元数据编目工具是对各种文档进行标引、分类等加工的工具,把各种类型的数字对象加工成有序资源,为数据库提供直观导航与多途径检索[9]。可标引文件格式包括:KDH、NH、PDF、CAJ、TXT、HTM、HTML、XML、EML、ASP、DOC、PPT、TIF、BMP、JPG、JPEG、GIF文件等。
内容管理器和元数据编目加工系统的数据库。内容管理器的模块分布分为:内容管理区、内容浏览器和菜单栏部分。内容管理区主要包括用户管理、数据管理、模板管理、分布式管理和模板信息。该内容区能查看的内容会受到管理员为用户所设置的权限限制。所能够执行操作的功能也是会受到管理员用户所设置的权限限制。按照张謇研究文献的类型,张謇研究文献数据库构建包括:张謇著述库、张謇研究著作库、张謇研究档案资料库、张謇研究期刊论文库、张謇研究学位论文库、张謇研究报纸论文库、张謇研究图片库、张謇研究多媒体资源库、张謇研究演示文稿等,此外还设计了张謇研究网络资源导航库等。
通过内容管理器在每个数据库中所提供的功能有:基本信息、字段信息、记录信息、分类导航4个部分。在记录信息部分中可以添加元数据,右键单击记录信息部分,会出现菜单栏,选择添加元数据会弹出字段信息的所有字段,用户可根据字段来填写字段内容,也可以连续添加或者对某字段内容打开修改。确定完善好字段信息之后点击确定就可以增加一条新的元数据编目数据。记录信息因为是所有元数据的集成地,所以当增加完成一条元数据之后,会在成千上万条元数据编目中存在。字段检索功能可以在最短的时间内找到最新增添的一条元数据。在内容管理器菜单栏中有记录下拉菜单栏可以选择记录检索,可以选择单项检索和组合检索。记录信息部分还可以将每个元数据的作为任务分发给服务器组中的用户,由管理员分发元数据编目的任务。管理员可以为每个成员设置对元数据操作的权限。

经过近20年的数据库建设,张謇研究数据库已经完成张謇研究著作库578部,张謇著述5926条,张謇研究期刊论文5861篇,张謇研究档案资料507件,张謇研究学位论文692篇,张謇研究会议论文1238篇,张謇研究报纸论文1969篇,张謇研究图片1023幅,张謇研究网络资料3017个等,具有跨库检索等多功能的张謇专题研究文献集合(见图2)。
张謇研究数据库建成以后,由于文献类型丰富、资料收集全、更新快,且地方特色鲜明,充分服务于地方经济文化建设,实用性强;同时软件选用符合CALIS标准,便于共享,数据组织、数据标引规范;检索途径多,界面友好方便,因而得到张謇研究学者的高度肯定。已经成为南通市江海文化、张謇研究的重要资源,并已在江苏省高校图书馆共享。
3.张謇研究数据库应用研究
3.1 张謇研究关键词共现网络研究
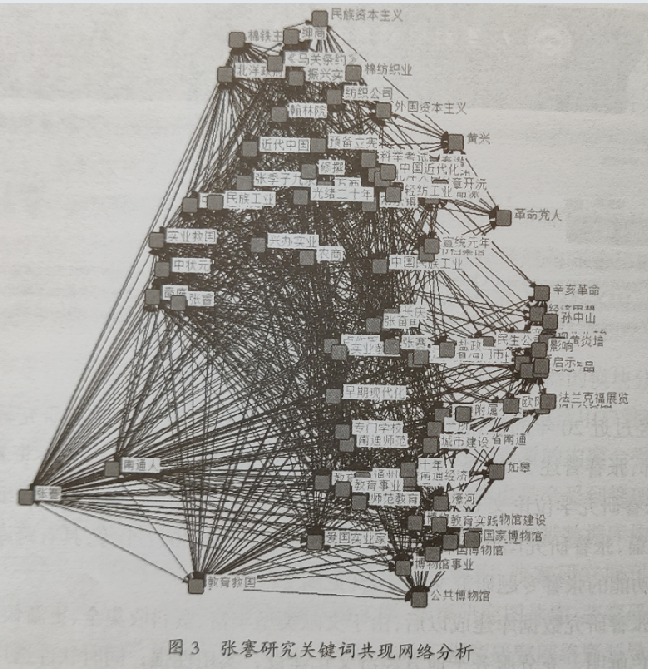
利用张謇研究数据库,可以通过社会网络分析工具进行关键词共现网络分析,作者群合作网络分析、研究引文和机构关联分析等基于数据库的张謇研究文献计量研究。例如,利用社会网络分析工具UCINET,分析张謇研究数据库中的期刊论文关键词共现网络分析,分析近30年张謇研究的热点趋势,如图3所示。
3.2 张謇学数字人文深度开发研究
在此基础上研究构建张謇学数字人文平台。平台自底向上分3个层次,包括信息资源层、整合支撑层和应用层。第一层是张謇研究信息资源层。首先,制定不同类型张謇学文献数据资源的加工规范。包括《张謇著述采集和加工规范》《张謇图像资源采集和加工规范》《张謇档案资源采集和加工规范》等。其次,制定张謇学文献数字化识别的参数标准、保存格式、方法步骤等规范。最后,构建张謇学文献知识库。数字资源采集和数字化加工系统支持基于众包参与的在线审校和提交方式。数据存储支持关联数据(RDF)格式转换和三元组存储的主流关系型数据库,系统遵循安全接口协议。第二层是张謇学文献资源整合支撑层。整合支撑平台的主要功能是获取和组织各种类型元数据规范,并通过网关接口和应用接口访问外部元数据,同时要求系统支持张謇语义词典的标注、张謇知识本体建模、命名实体抽取和存储,实现关系数据库到关联数据(RDF)的映射转换。第三层是张謇学文献数字人文服务应用层。张謇学稀见文献发现研究。首先,基于张謇学稀见文献的属性特征,将张謇学文献与文献中的实体知识进行关联,通过关联发现更多的文献线索,不断丰富张謇学文献。其次,为人文学者利用微博、推特和其他社交媒介创建学者圈、主题社区,关联相关的学术博客、网站和个人空间并通过用户注册实现张謇濒危稀见文献资源的个性化推送,促进张謇学稀见文献网络化传播与利用[10]。
4.结束语
南通大学图书馆长期致力于张謇稀见文献的收集、整理与保护,构建张謇文献数据库,利用数字化技术、语义知识组织工具和人工智能新方法对张謇文献进行数字化保护和利用。在收集张謇稀见文献的过程中,综合利用国内外先进的古籍数字人文平台和古籍资源库,如上海图书馆古籍联合目录及循证平台、哈佛大学哈佛燕京图书馆藏中文善本特藏资源库、东京大学东洋文化研究所汉籍全文影像数据库等,收集张謇手稿、档案、信札、诗文等原始文献。采用机器OCR识别辅助人工校对张謇稀见文献,将图像文件转为可编辑的文档,再利用关键词精准定位整理古籍文献。通过关系图谱链接人物、地域以及时间,关联多种资源类型数据进行展示,把文化背后的关系找出来并以图的方式显示。目前已经收集整理稀见张謇手稿、信札、诗文、档案、地方志、著述等一千余种。同时通过知识图谱推理,发现更多文献证据链,考证和发现更多散佚民间和域外的珍本、孤本、手稿、信札、档案等濒危文献。为了将书写在古籍里的文字都活起来,探索运用GPT类技术融入虚拟博物馆,让“中国近代第一城”活起来,提供超越时空、沉浸式、集中的展览,丰富用户的文化体验。用户能够通过虚拟现实技术人机交互式参观博物馆等文化遗产场所,感受南通近代濒危历史遗迹的生命力。本文概述了南通大学张謇研究文献数据库的建设背景、收录范围、数据库的平台架构,功能结构,张謇研究文献数字化过程中的电子书加工与元数据编目操作流程以及检索功能的实现。在此基础上进一步提出了利用张謇研究数据库进行张謇研究社会网络分析和基于本体的张謇研究与江海文化深度开发的构思与应用。以大数据、人工智能技术为依托,整理分析文献与文献、文献与人物、人物与人物之间关联关系,为“讲好张謇故事、传承张謇精神”提供一套完整的知识管理平台。
参考文献:
[1]张謇-百度百科[EB/OL].(2006-4-27)[2023-07-09].https://baike.baidu.com/item/张謇/1129763?fromModule=lemma_search-box.
[2]徐晨飞,倪媛,钱智勇.基于本体的“江海文化”文献知识组织体系构建研究[J].现代情报,2015,35(10):62-71.
[3]高研院组织召开“第七届张謇国际学术研讨会”筹备会议.[EB/OL].(2022-09-18)[2023-7-9].https://ias.nju.edu.cn/f5/a3/c13160a587171/page.htm.
[4]端木艺.特色数据库的内容揭示:以基于TPI平台的张謇研究特色数据库为例[J].中国索引,2009,7(1):50-53.
[5]李筑宁.关于古籍资源数字化建设中几个问题的探讨[J].图书情报工作,2010(S1):312-315.
[6]林水灿.利用TPI系统建设教学参考信息数据库:兼论厦门理工学院“教学参考信息数据库”的建设[J].计算机光盘软件与应用,2012(9):225-227.
[7]邓嘉墚.纸质档案数字化质量控制与管理[D].苏州:苏州大学,2017.
[8]姜莹莹,刘佳音.高校图书馆航空特色资源库建设实践与思考:以南京航空航天大学为例[J].情报探索,2018(8):83-87.
[9]周林兴,张笑玮.基于信息组织维度的公共档案馆社会影响力建构探析[J].兰台世界,2022(5):26-33.
[10]徐毅.面向国家文化数字化战略的图书馆创新实践:以张謇学濒危稀见文献数字化保护和利用为例[J].新世纪图书馆,2022(11):20-29,96.
课题来源:南通市社科基金“人文数字视野下张謇知识模型构建研究”(课题编号:2022CNT044)成果。
作者简介:李强(1979-),男,江苏南通人,硕士,副研究馆员,研究方向:数字人文方向。
(原刊于《文化创新比较研究》2023年第8期(b),85~90页)